Learning Canonical Representations for Scene Graph to Image Generation
ECCV, 2020
*Equally contributed
|
1Tel-Aviv University 2UC Berkeley 3Bar-Ilan University, NVIDIA Research
|
Generating realistic images of complex visual scenes becomes challenging when one wishes to control the structure of the generated images.
Previous approaches showed that scenes with few entities can be controlled using scene graphs,
but this approach struggles as the complexity of the graph (the number of objects and edges) increases.
In this work, we show that one limitation of current methods is their inability to capture semantic equivalence in graphs.
We present a novel model that addresses these issues by learning canonical graph representations from the data,
resulting in improved image generation for complex visual scenes.
Our model demonstrates improved empirical performance on large scene graphs, robustness to noise in the input scene graph,
and generalization on semantically equivalent graphs.
Finally, we show improved performance of the model on three different benchmarks: Visual Genome, COCO, and CLEVR.
Our contributions are thus:
1) We propose a model that uses canonical representations of SGs, thus obtaining stronger invariance properties.
This in turn leads to generalization on semantically equivalent graphs and improved robustness to graph size and noise in comparison to existing methods.
2) We show how to learn the canonicalization process from data.
3) We use our canonical representations within an SG-to-image model and demonstrate our approach results in an improved generation on Visual Genome, COCO, and CLEVR, compared to the state-of-the-art baselines.
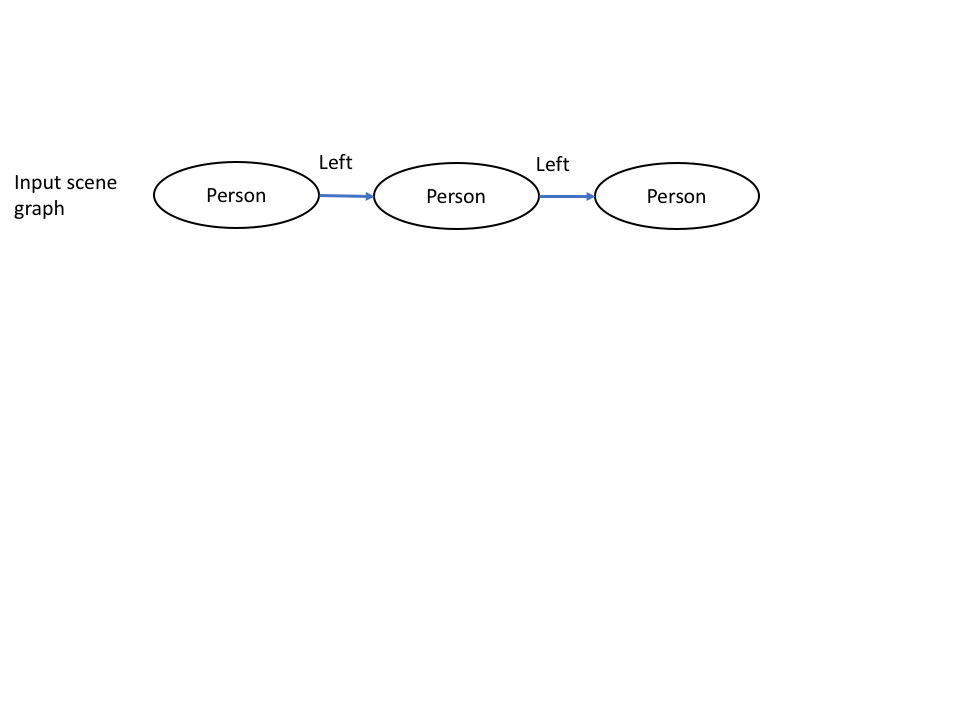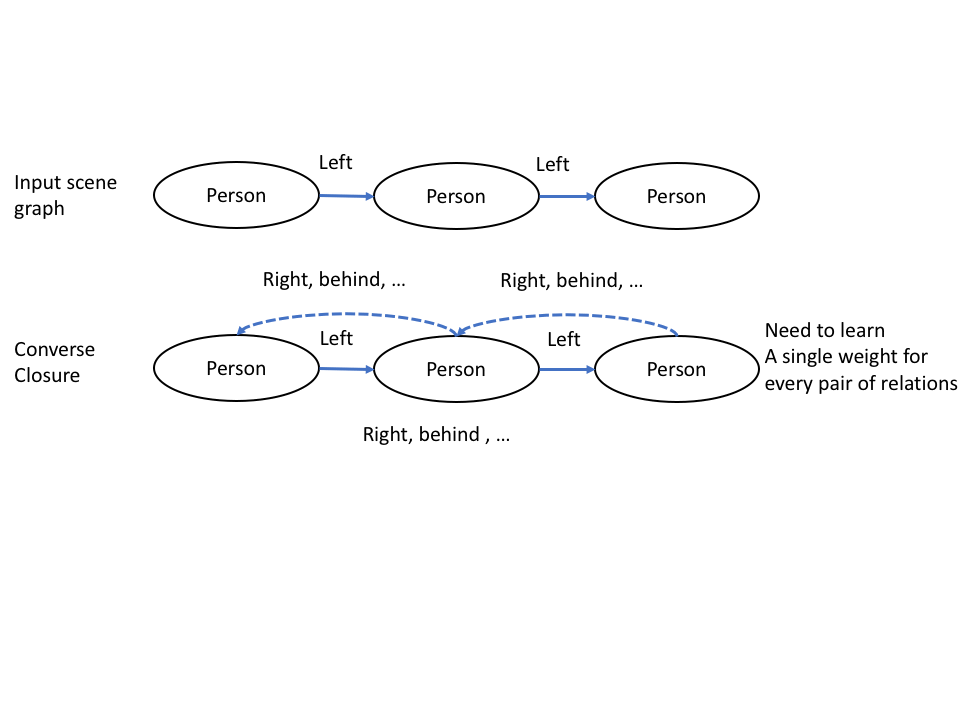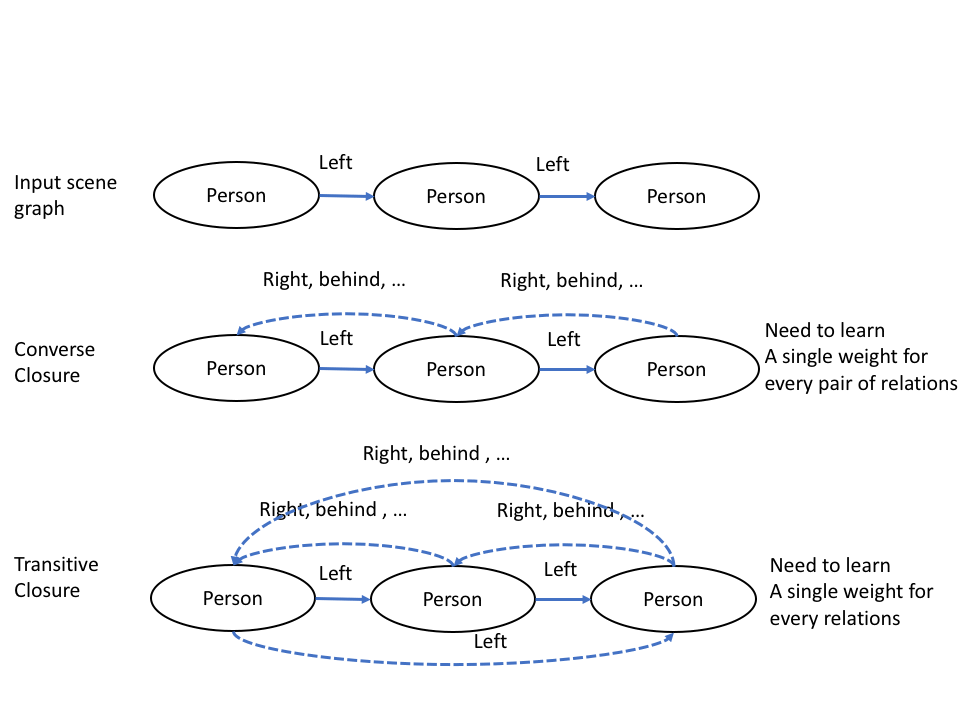
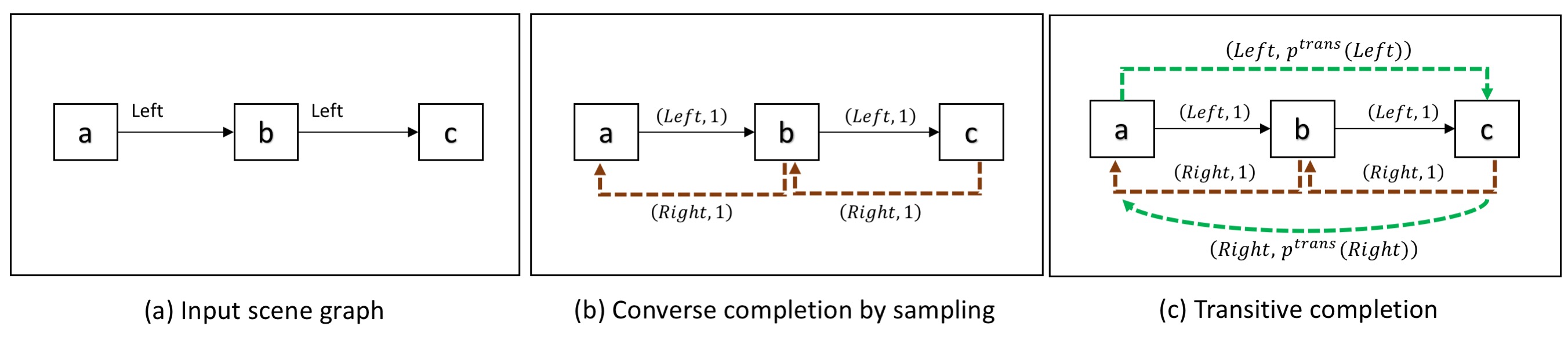
Scene Graph Canonicalization
We propose an approach to canonicalize graphs to enforce invariance to these equivalences since multiple logically equivalent SGs can represent the same image.
Given an input of SG, our model calculated a weighted canonicalized graph, followed a GCN for generating robust layouts.
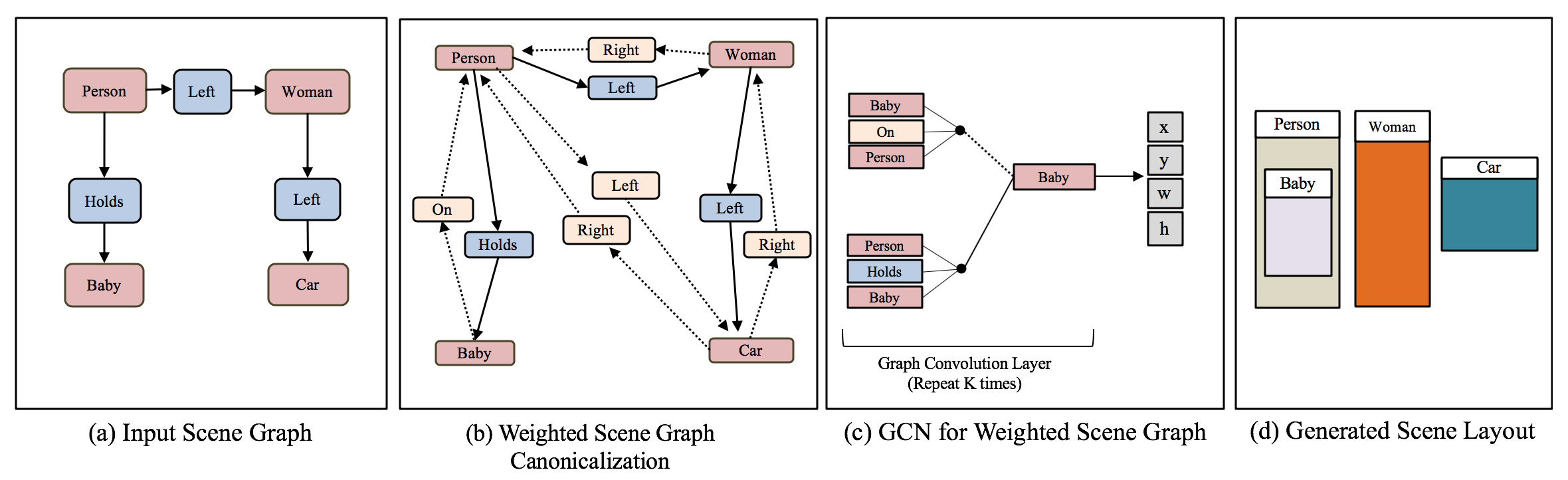
Given the input graph, two weighted completion steps are performed.
The first step is the Converse Completion: Anti-symmetry relations are added with its corresponding converse weight (e.g., R(left, right)).
The second step is the Transitive Completion: Transitive relations are added, and we set the weight to be the product of weights.
Finally, the model learns to form the canonical graph.
Here an example of the process.
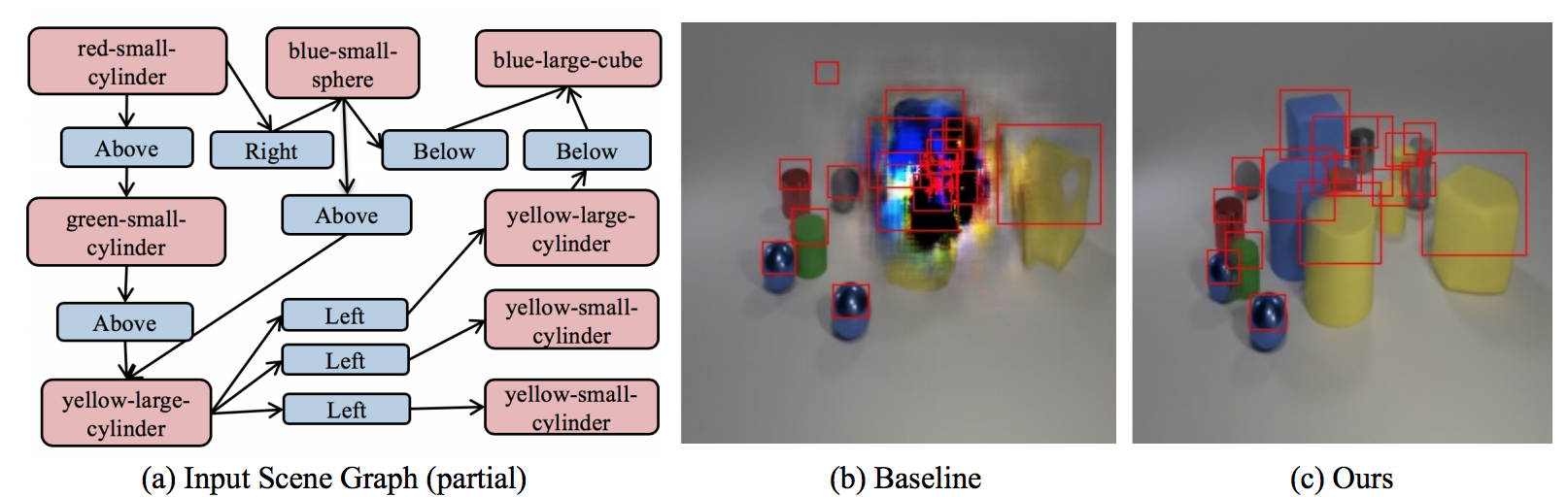
Generation with large graph sizes
We show our model generalizes over the number of objects in the graph.

For example, the baseline and our model were trained on a fixed number of objects,
but when tested on a large number, the baselines collapse (top row vs. down row).
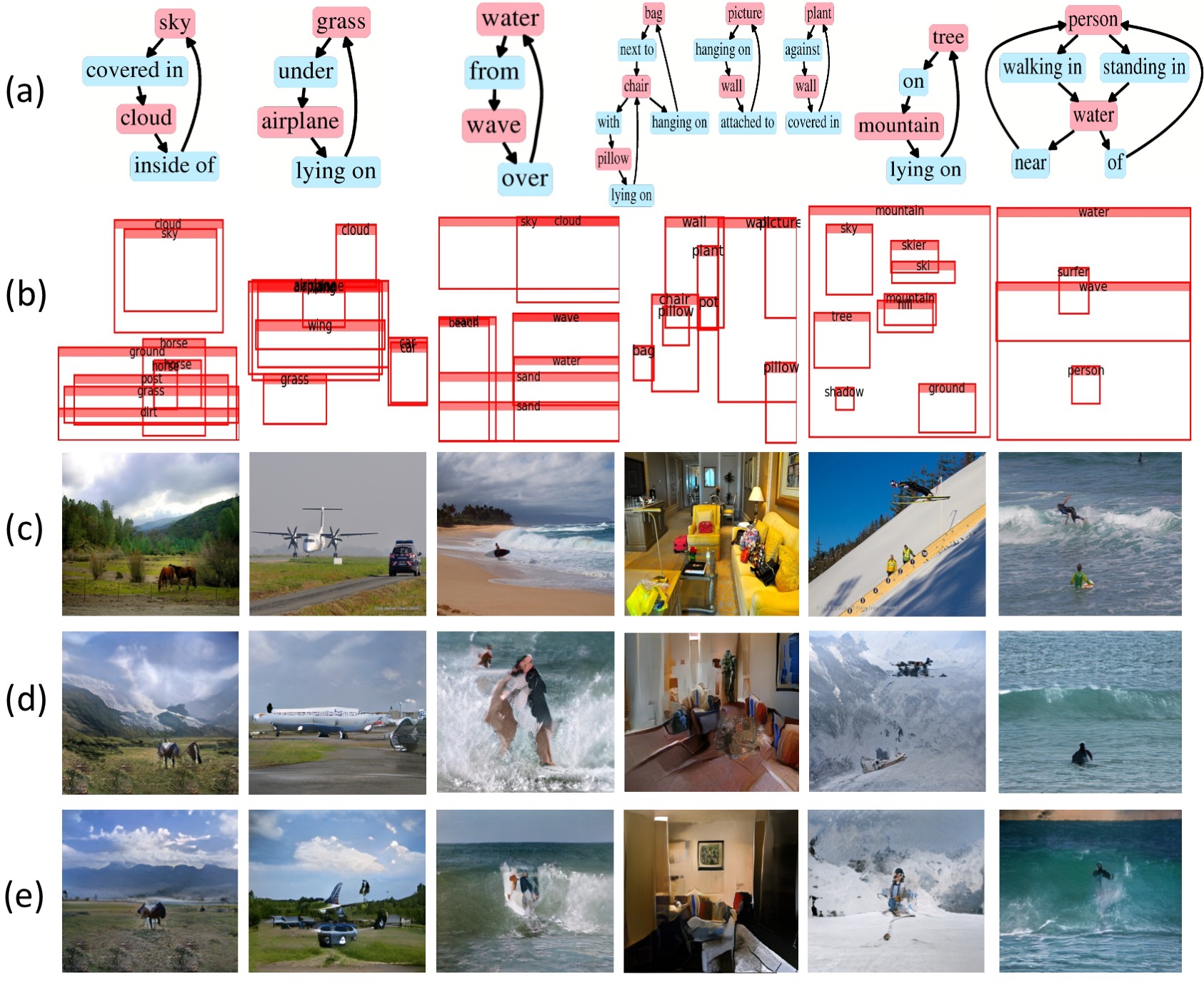
Generalization on semantically equivalent graphs
A key advantage of our model is that it produces similar layouts for semantically equivalent graphs.
To achieve this, we generate a semantically equivalent SG by randomly choosing to include/exclude edges
that don't change the semantics.
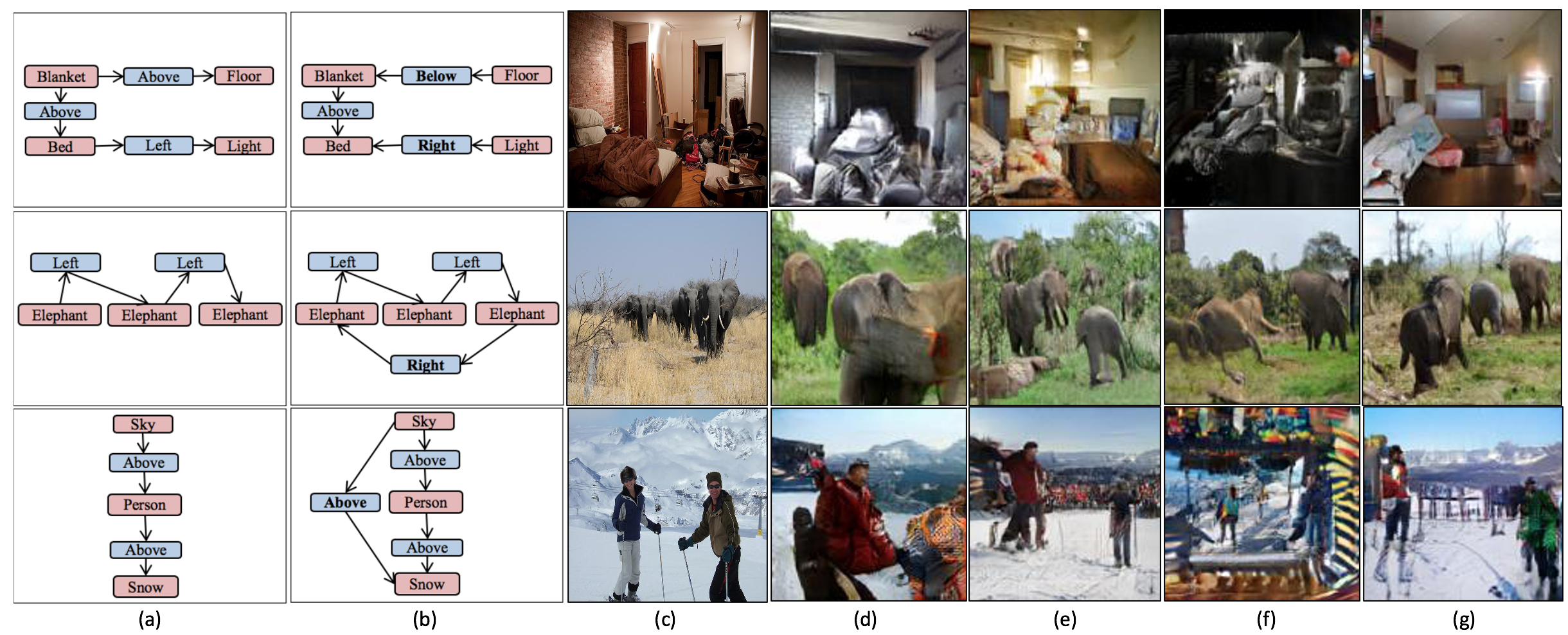
Each input SG is changed to a semantically equivalent SG at test time.
The layout-to-image model is LostGAN and different SG-to-layout models are tested.
(a) Original SG (partial). (b) A modified semantically equivalent SG (partial). (c) GT image.
(d-e) Sg2Im and WSGC for the original SG. (f-g) Sg2Im and WSGC for the modified SG.
Robustness to noise in the input scene graph
Conflicting edges in the input SG could be due to unintended or adversarial modifications.
We analyze how modifications affect the model by randomly modifying 10% of the relations.
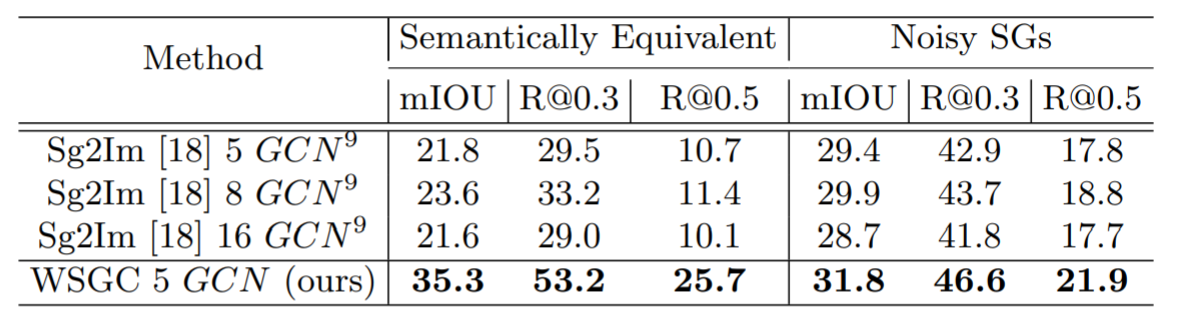
We evaluate the robustness of the learned Canonical Representation for models which were trained on Packed COCO (images with 16+ objects in COCO).
We compare our WSGC model to the Sg2Im baseline with a GCN of 5 layers and even more.
It can be seen that increasing the GCN size comes at the price of overfitting.
The key idea in the AttSPADE model is to condition generation on the attributes,
as opposed to only the object class as done in current models.
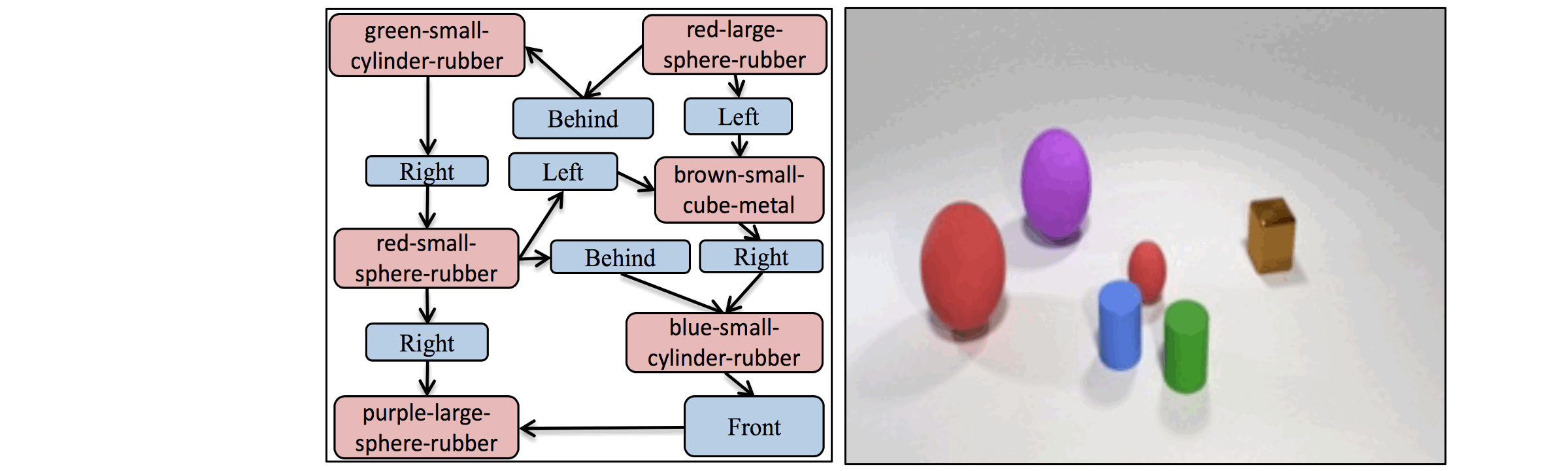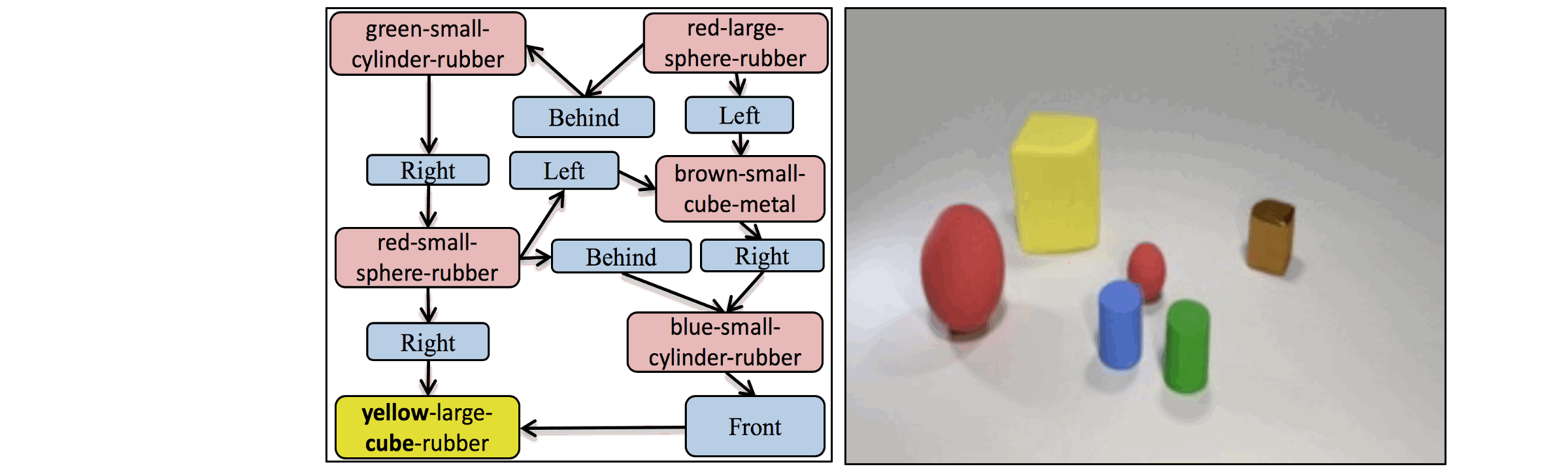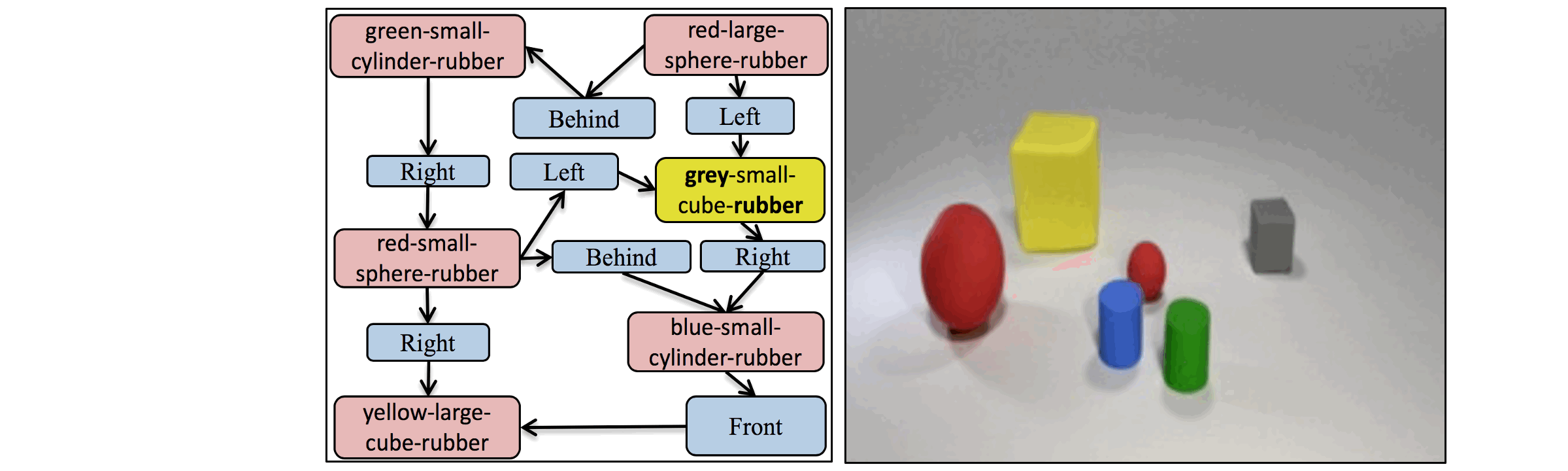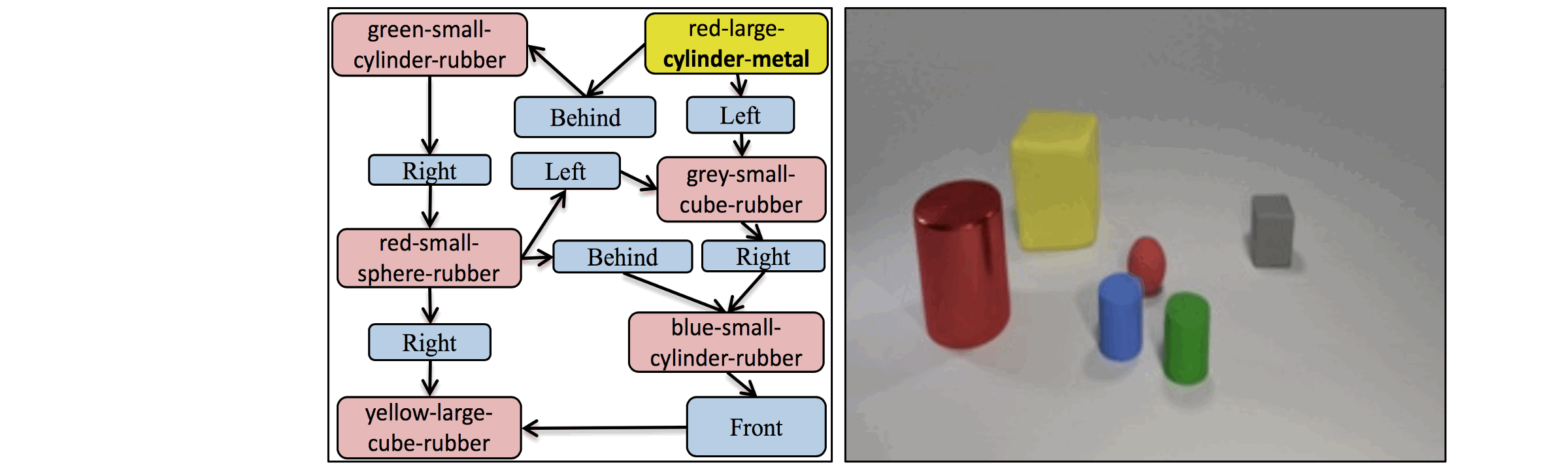
A demonstration of the AttSPADE that by manipulating the attributes of the objects,
the scene is generated accordingly.

Selected GT layout-to-image generation results on COCO-Stuff dataset on 128x128 resultion.
Here, we compare our AttSPADE model, Grid2Im and LostGAN on generation from GT layout of masks.
(a) GT layout (only masks). (b) GT image. (c) Generation with LostGAN model. (d) Generation with Grid2Im.
(e) Generation with AttSPADE model (ours).

Selected generation results on the COCO-Stuff dataset at 256x256 resolution.
Here, we compare our AttSPADE model and Grid2Im in two different settings:
generation from GT layout of masks and generation from scene graphs.
(a) GT scene graph. (b) GT layout (only masks). (c) GT image. (d) Generation with Grid2Im using the GT layout.
(e) Generation with Grid2Im No-att from the scene graph (GT layout not used).
(f) Generation with AttSPADE model (ours) using the GT layout.
(g) Generation with WSGC + AttSPADE model (ours) from the scene graph (GT layout not used).
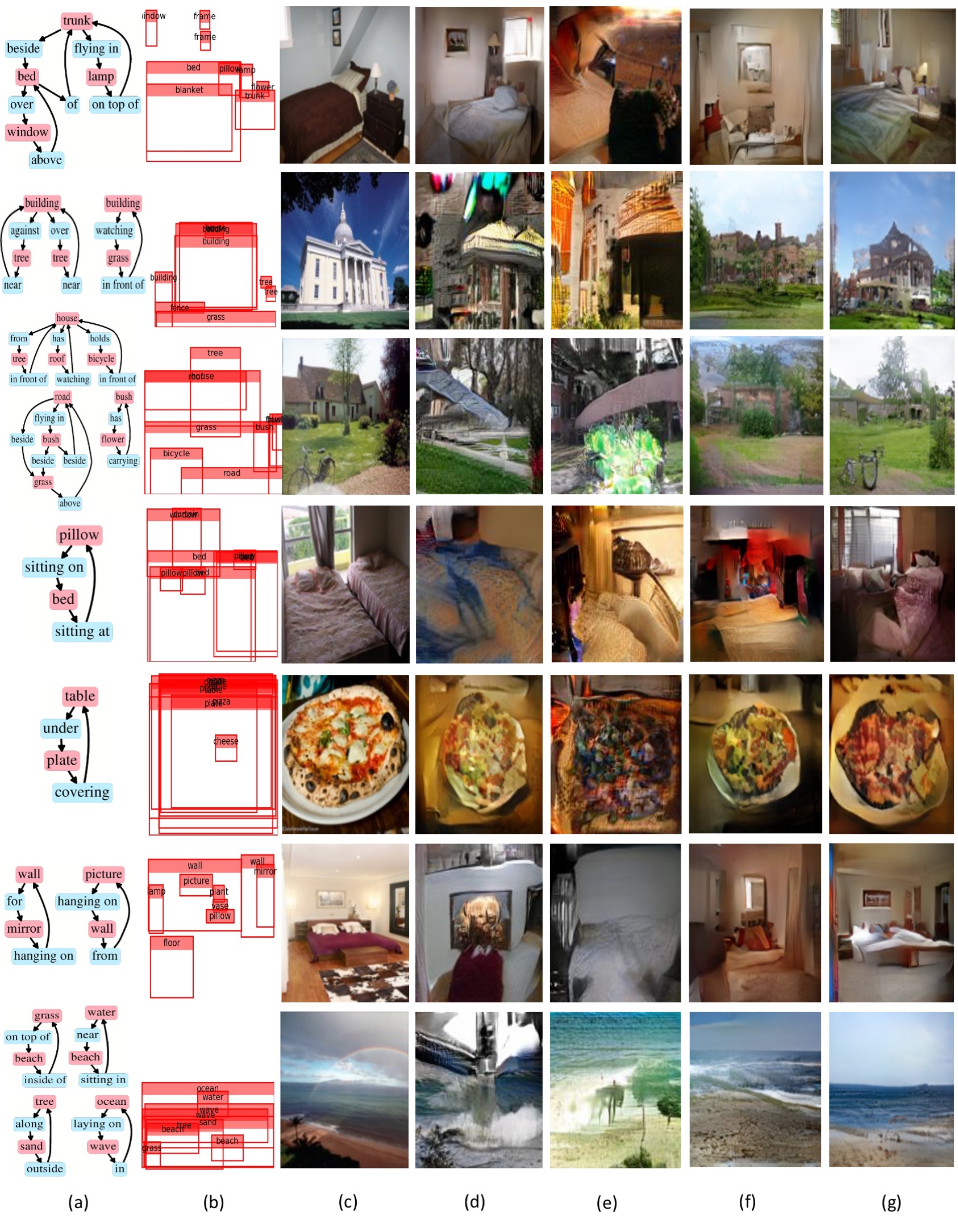
Selected scene-graph-to-image results on Visual Genome dataset on 128x128 resolution.
Here, we compare our AttSPADE model and LostGAN in two different settings:
generation from GT layout of boxes and generation from scene graphs.
(a) GT scene graph. (b) GT layout (only boxes). (c) GT image. (d) Generation using LostGAN from the GT layout.
(e) Generation with the WSGC + LostGAN from the scene graph (GT layout not used).
(f) Generation with the AttSPADE model (ours) from the GT Layout.
(g) Generation with the WSGC + AttSPADE model (ours) from the scene graph (GT layout not used).
Selected scene-graph-to-image results on the Visual Genome dataset at 256x256 resolution.
Here, we test our AttSPADE model in two different settings: generation from GT layout of boxes and generation from scene graphs.
(a) GT scene graph. (b) GT layout (only boxes). (c) GT image.
(d) Generation with the AttSPADE model (ours) from the GT Layout.
(e) Generation with the WSGC + AttSPADE model (ours) from the scene graph (GT layout not used).
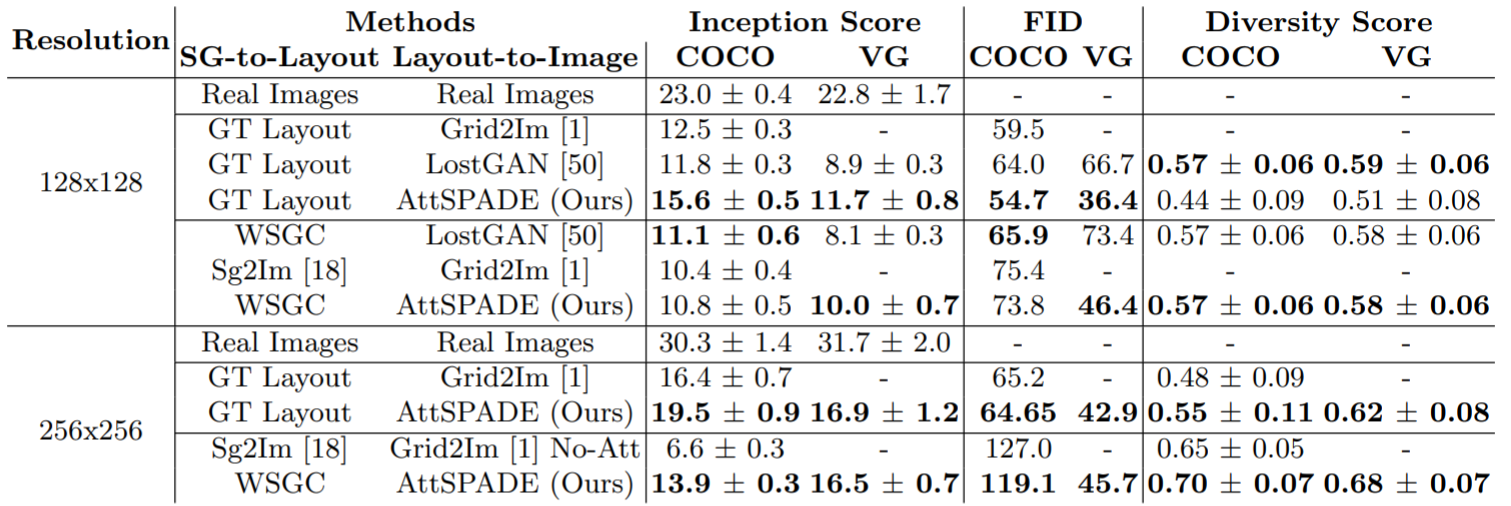
Quantitative comparisons for SG-to-image methods using Inception Score (higher is better),
FID (lower is better) and Diversity Score (higher is better).
Evaluation is done on the COCO-Stuff and VG datasets.
Paper
 |
|
Roei Herzig*, Amir Bar*, Huijuan Xu, Gal Chechik, Trevor Darrell, Amir Globerson
Learning Canonical Representations for Scene Graph to Image Generation
In ECCV, 2020
Hosted on arXiv
*Equal contribution
|
@InProceedings{herzig2019canonical,
title = {Learning Canonical Representations for Scene Graph to Image Generation},
author = {Herzig, Roei and Bar, Amir and Xu, Huijuan and
Chechik, Gal and Darrell, Trevor and Globerson, Amir},
booktitle = {European Conference on Computer Vision},
year = {2020},
}
Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Unions Horizon 2020 research
and innovation programme (grant ERC HOLI 819080). Prof. Darrell's group was supported in part by DoD, NSF, BAIR, and BDD.
We would also like to thank Xiaolong Wang for comments on drafts.
|