Compositional Video Synthesis with Action Graphs
ICML 2021
*Equally contributed
|
1Tel-Aviv University 2UC Berkeley 3UC San Diego 4Bar-Ilan University, NVIDIA Research
|
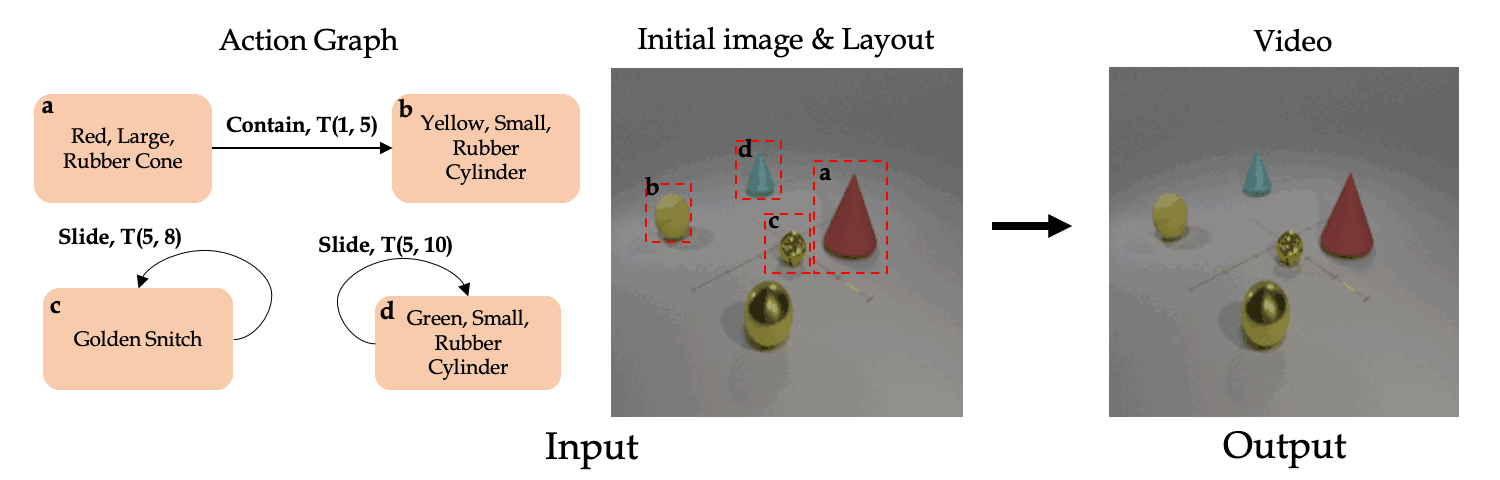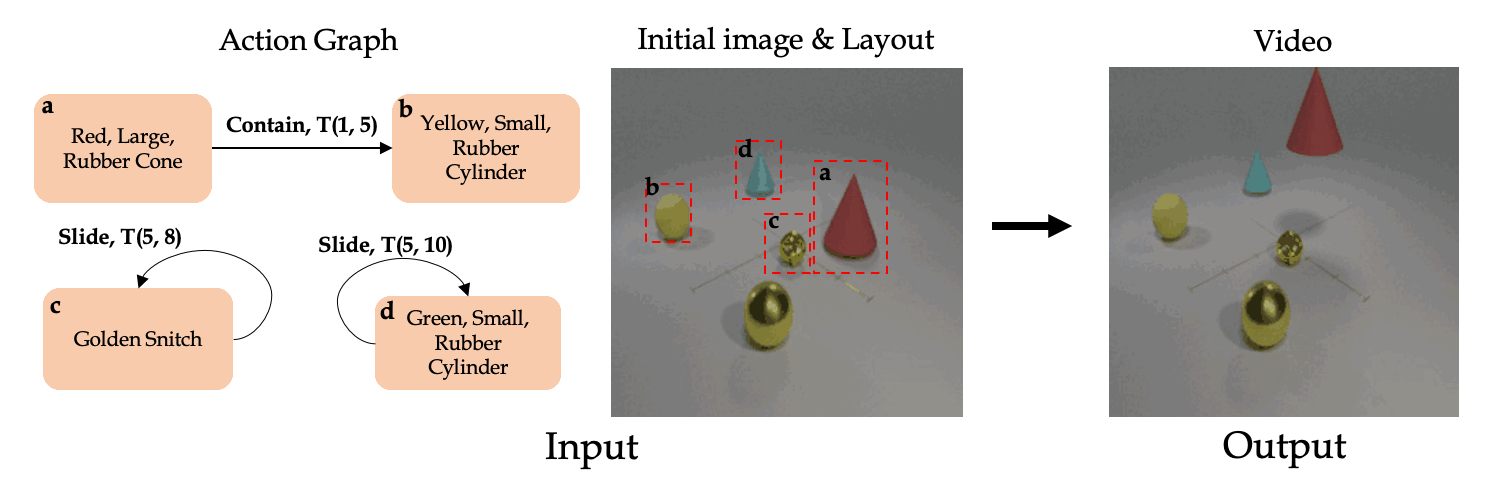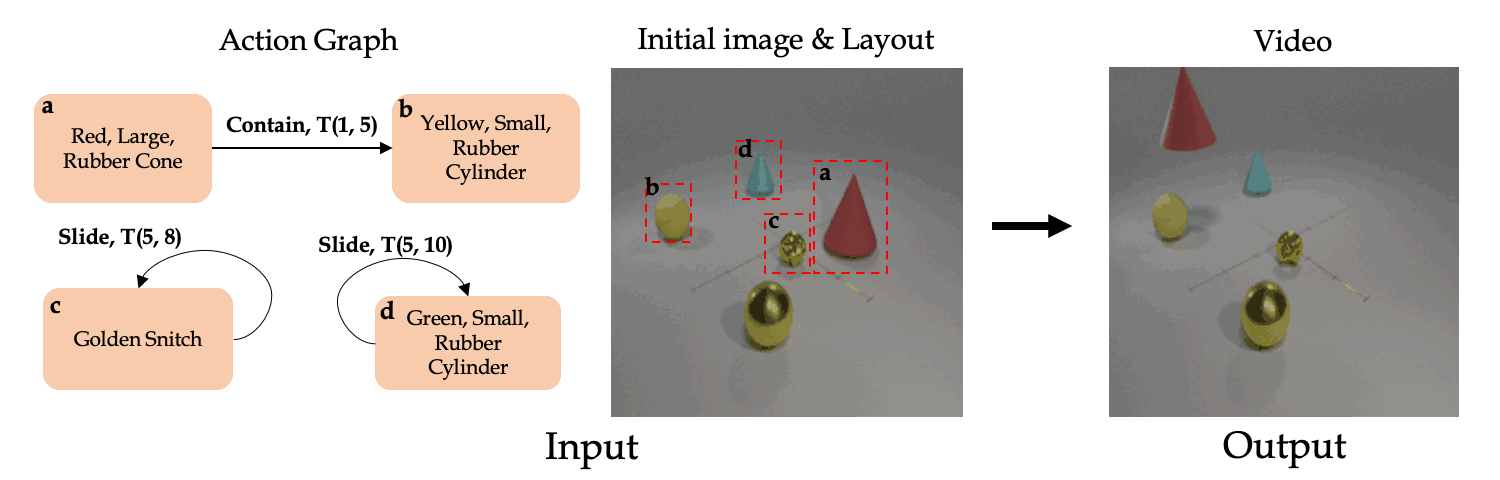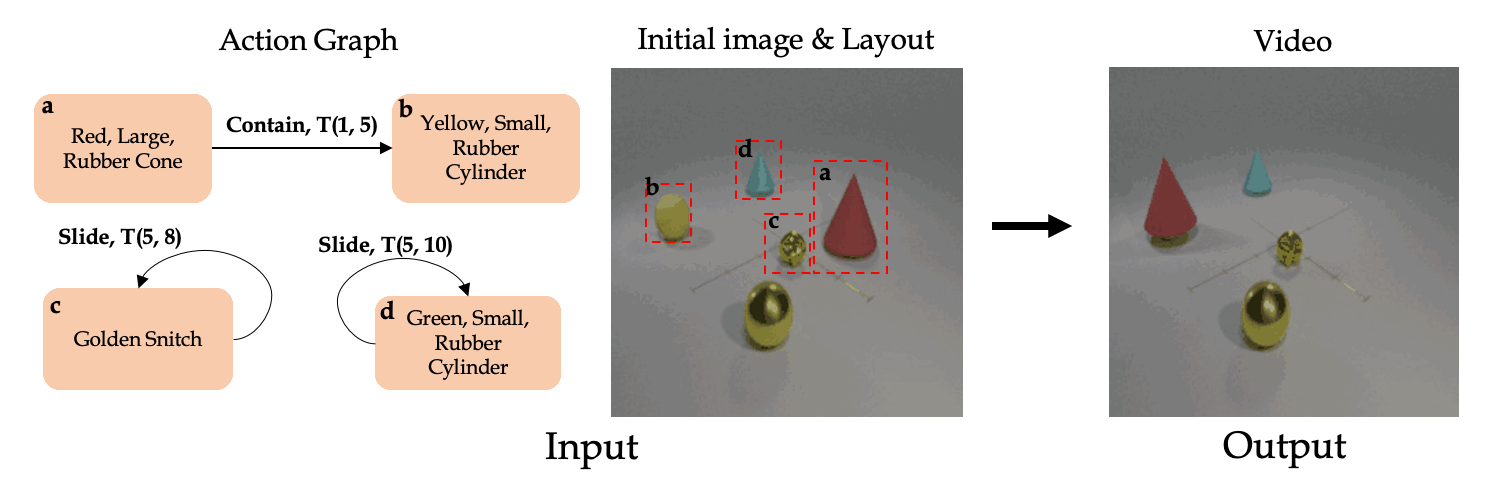
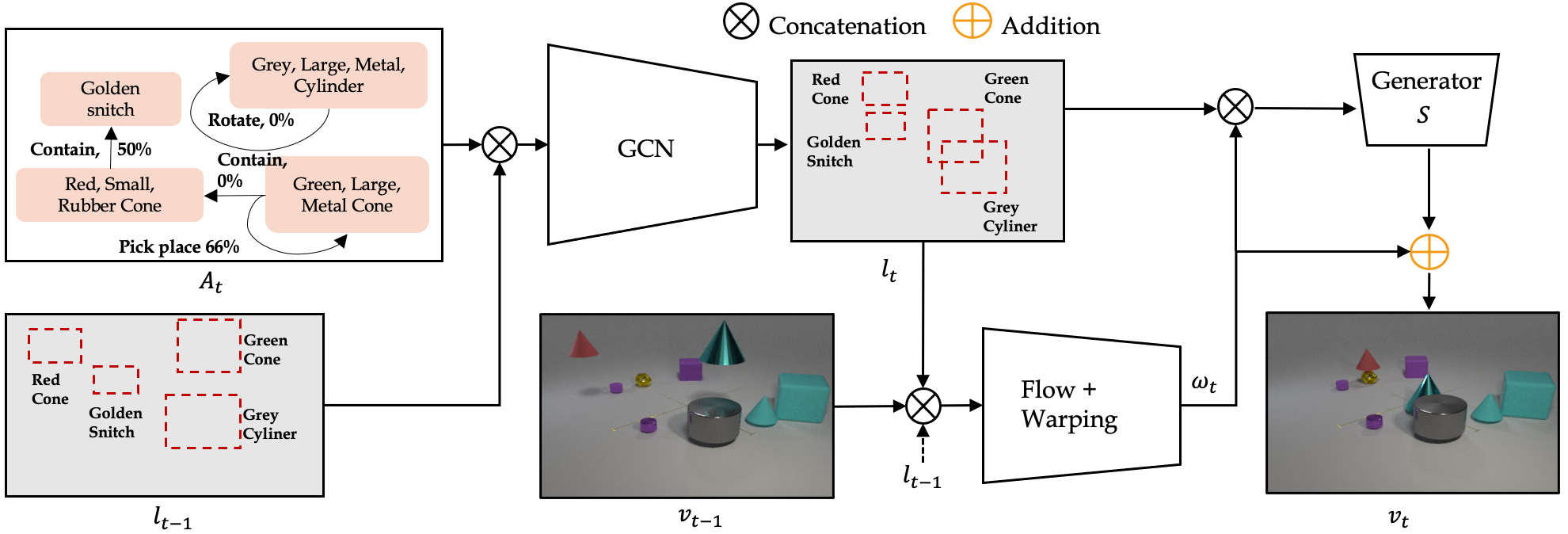
Our main goal is to learn to synthesize videos of actions. More specifically, our model should be able to synthesize videos given multiple (potentially simulatnious) timed actions with multiple number of objects. Towards this end, we present the Action Graph (AG) structure which we use to represent timed actions and objects, and the AG2Vid model which can synthesize videos conditioned on actions given in AGs and initial image and layout.
Classic work in cognitive-psychology argues that actions (and more generally events) are bounded regions of space-time and are composed of atomic action units (Quin, 1985; Zacks and Tversky, 2001). In a video, multiple actions can be applied to one or more objects, changing the relationships between the object and the subject of an action over time. Based on these observations, we introduce a formalism we call an Action Graph, a graph where nodes are objects, and the edges are actions specified by their start and end time.
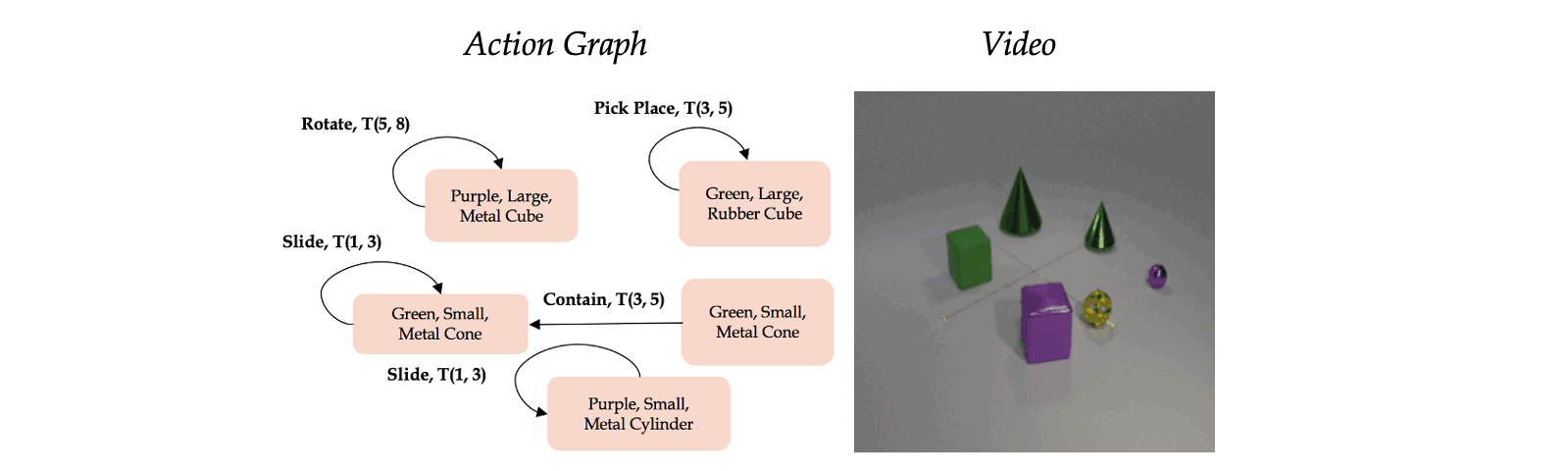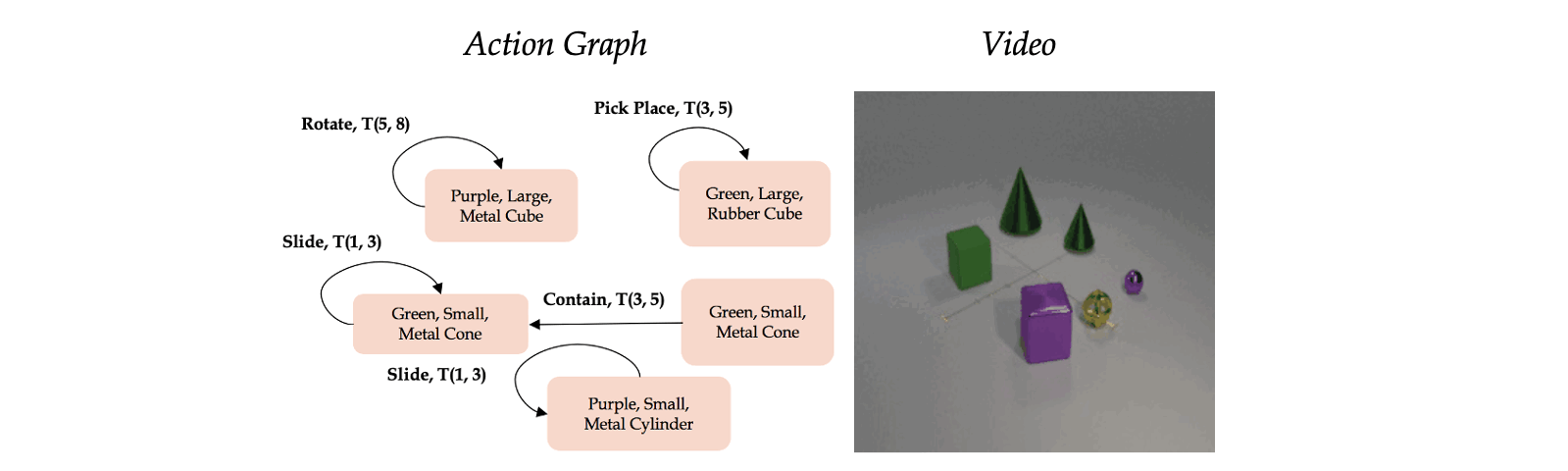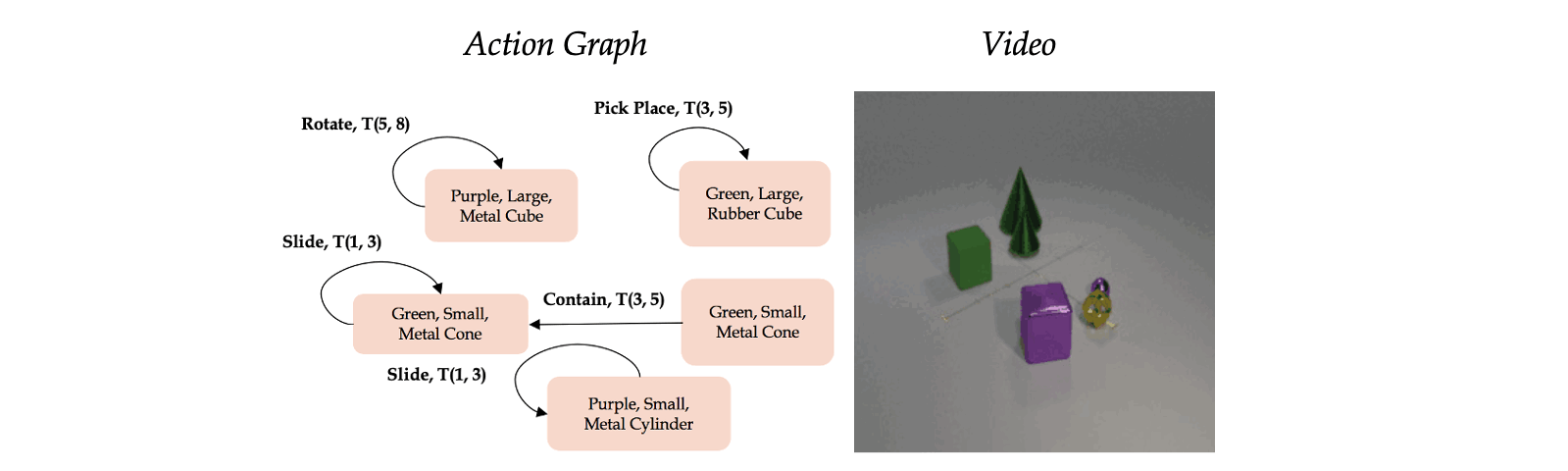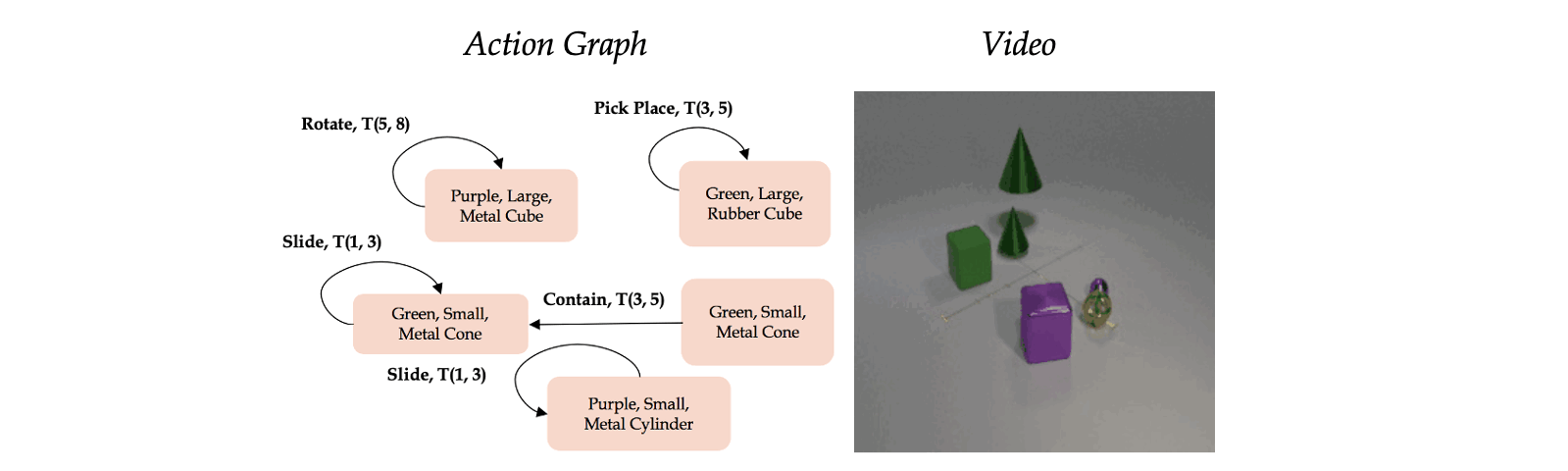
Action Graph is a natural and convenient structure representing the dynamics of actions between objects over time.

Qualitative examples for the generation of actions on the CATER and Something-Something V2 datasets.
We use the AG2Vid model to generate videos of multiple (potentially simultanious) actions on CATER and single actions on Something-Something V2.
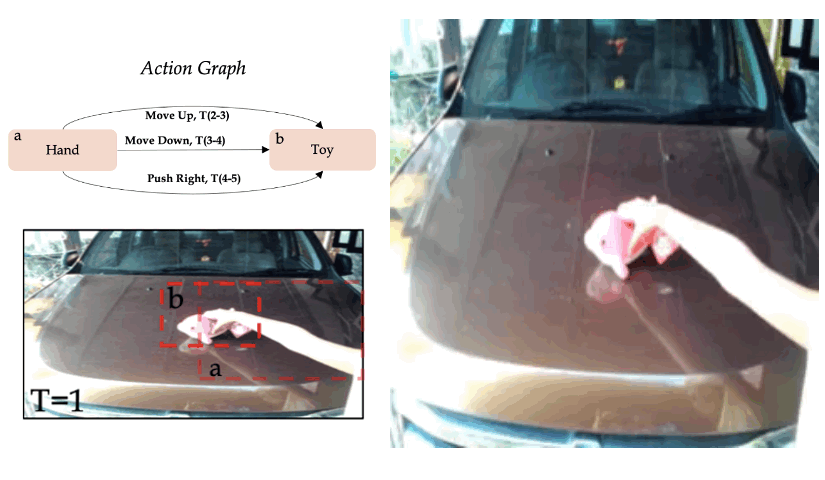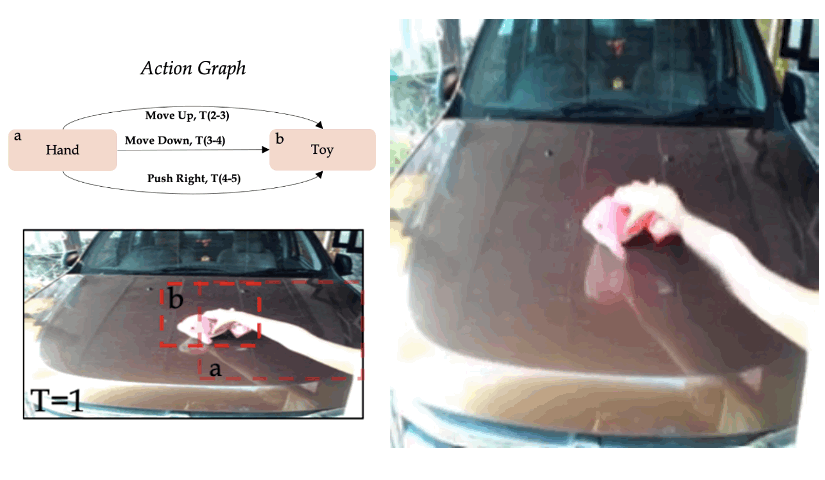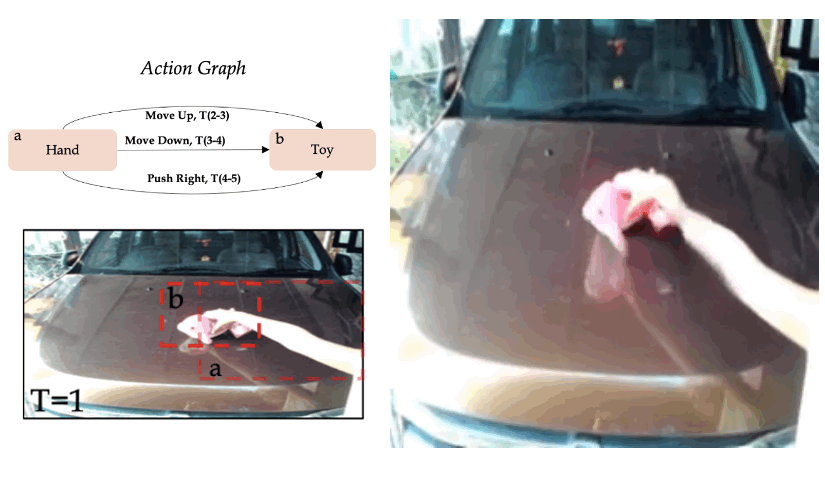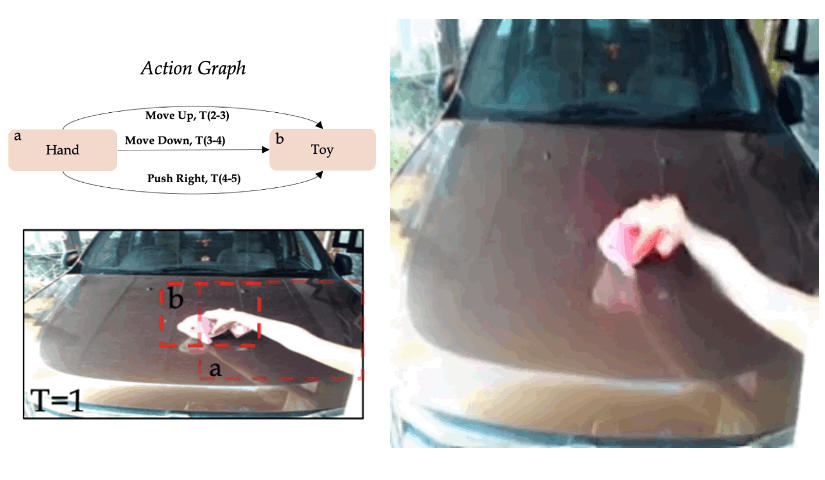
Zero-shot synthesis of sequential actions
We use the model trained on single actions on the Something-Something V2 dataset, and define more complex actions graphs, which contain sequential actions. In the given example, we define the sequence "Move up", "Move down", and "Move right".
Zero-shot synthesis of simultaneous actions
We use the model trained on single actions on the Something-Something V2 dataset, and define more complex actions graphs, which contain simultaneous actions. In the given example, we define the actions "Move right", "Move left" simultaneously.
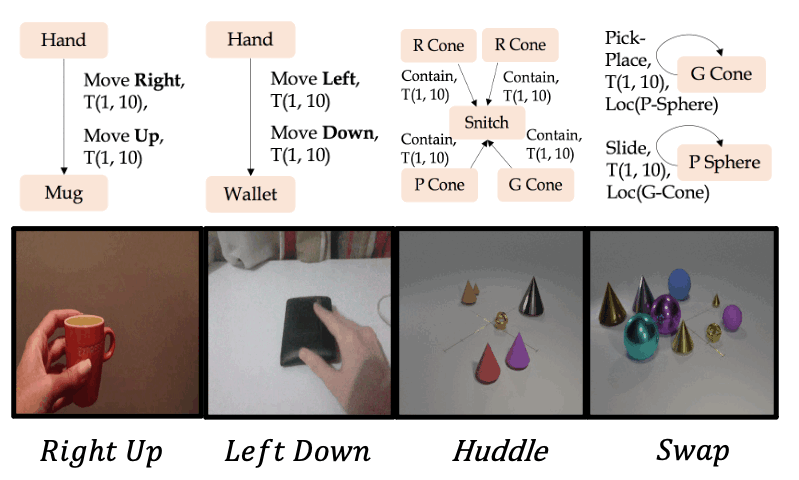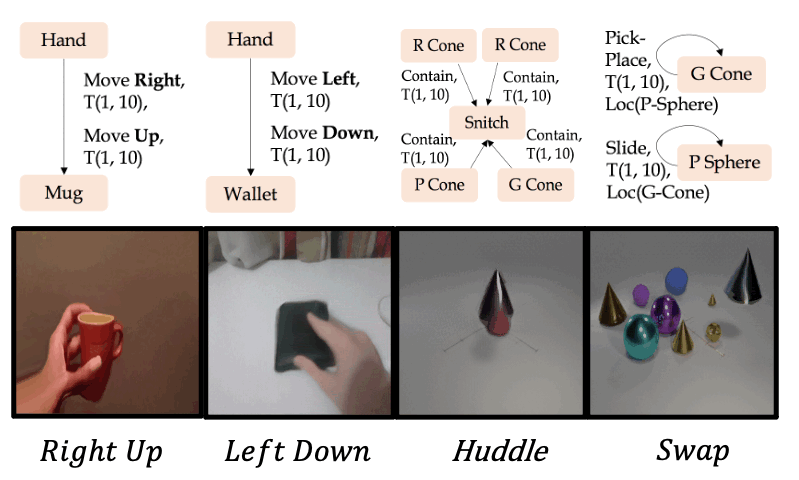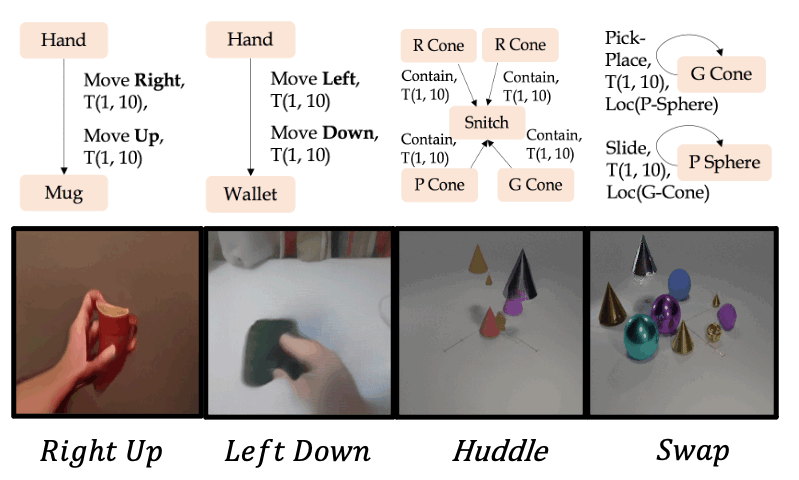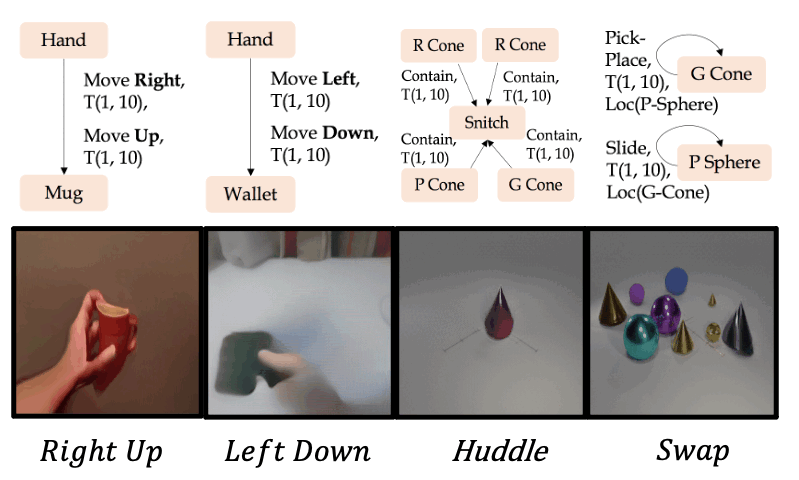
Zero-shot synthesis of new action composites
Qualitative examples for the generation of new action composites on the Something-Something V2 and CATER datasets.
We use the Action Graph representation to define 4 new action composites out of the existing actions, and use our AG2Vid model to generate corresponding videos.
Paper
 |
|
Amir Bar*, Roei Herzig*, Xiaolong Wang, Anna Rohrbach, Gal Chechik, Trevor Darrell, Amir Globerson
Compositional Video Synthesis with Action Graphs
ICML 2021
Hosted on arXiv
*Equal contribution
|
Related Works
Our work builds and borrows code from multiple past works such as SG2Im, Canonical-SG2IM and Vid2Vid. If you found our work helpful, consider citing these works as well.
|
Acknowledgements
We would like to thank Lior Bracha for her help running MTurk experiments, and to Haggai Maron and Yuval Atzmon for helpful feedback and discussions. This project has received funding from the European Research Council (ERC) under the European Unions Horizon 2020 research and innovation programme (grant ERC HOLI 819080). Trevor Darrell’s group was supported in part by DoD including DARPA's XAI, LwLL, and/or SemaFor programs, as well as BAIR's industrial alliance programs. Gal Chechik's group was supported by the Israel Science Foundation (ISF 737/2018), and by an equipment grant to Gal Chechik and Bar-Ilan University from the Israel Science Foundation (ISF 2332/18). This work was completed in partial fulfillment for the Ph.D degree of Amir Bar.
|