CVPR 2022
|
|
|
|
|
|
|
|
|
|
|
|
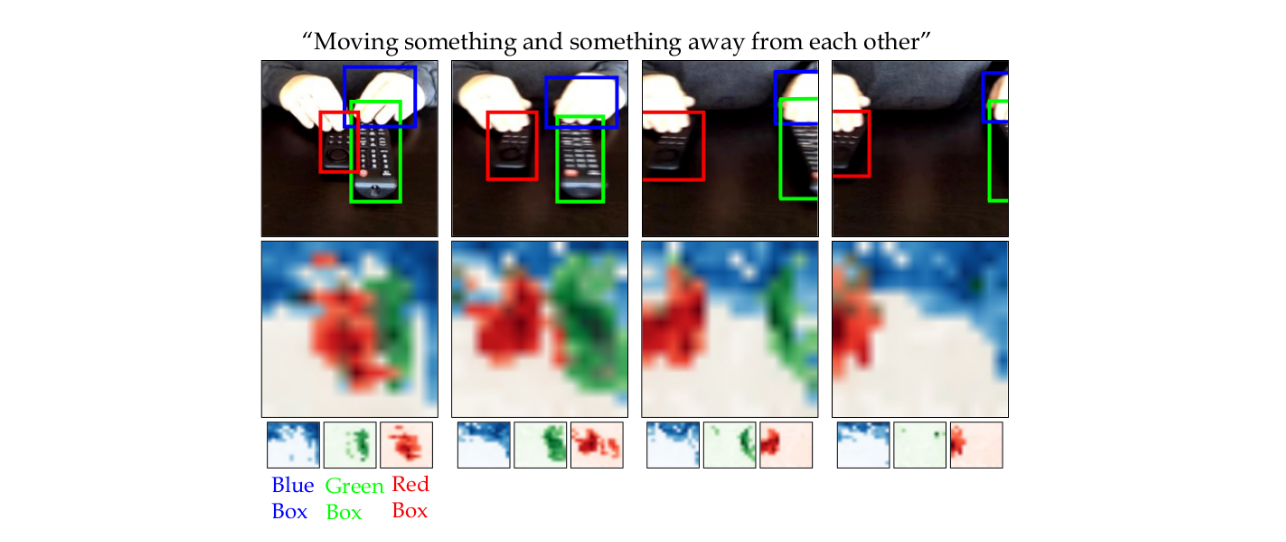
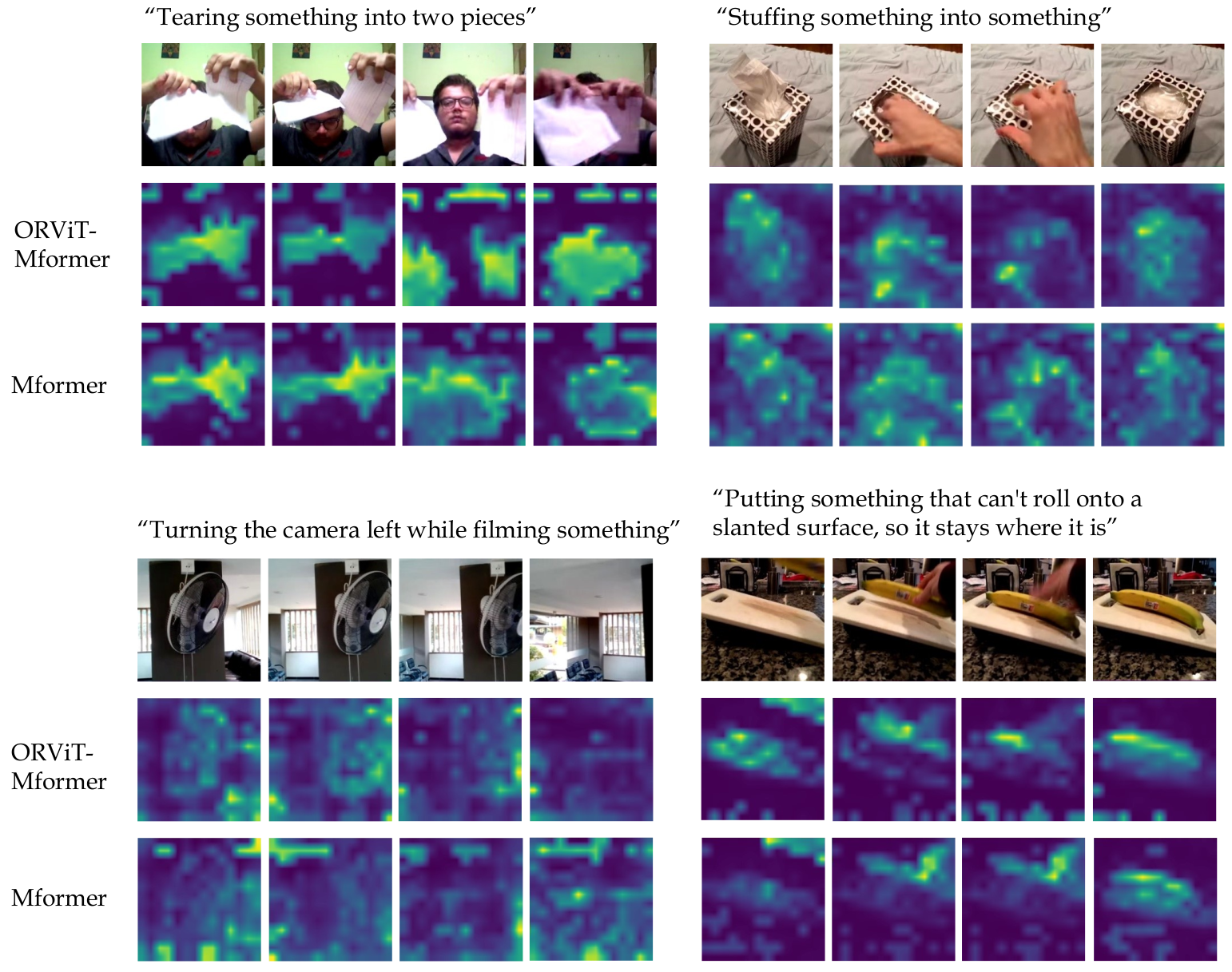
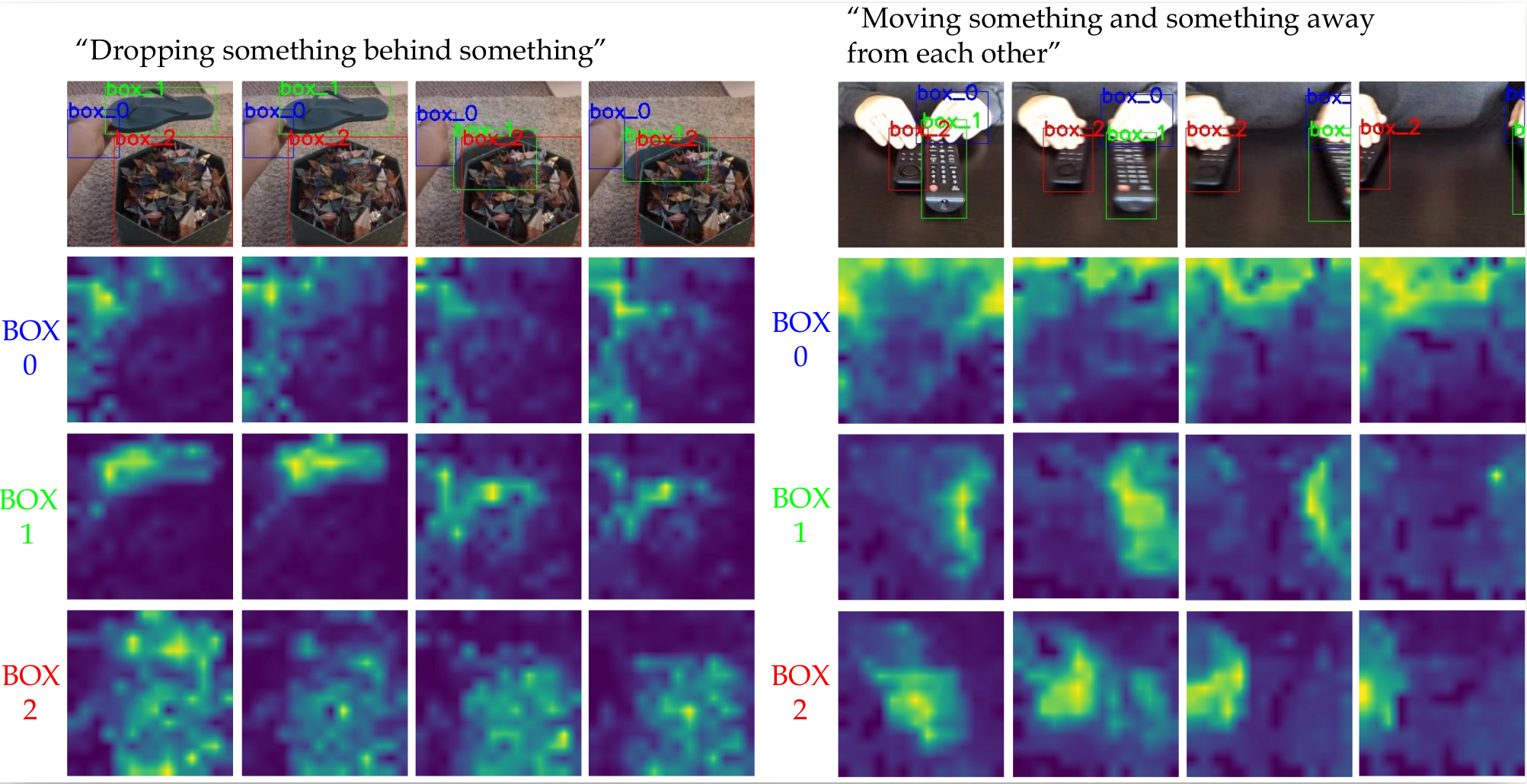
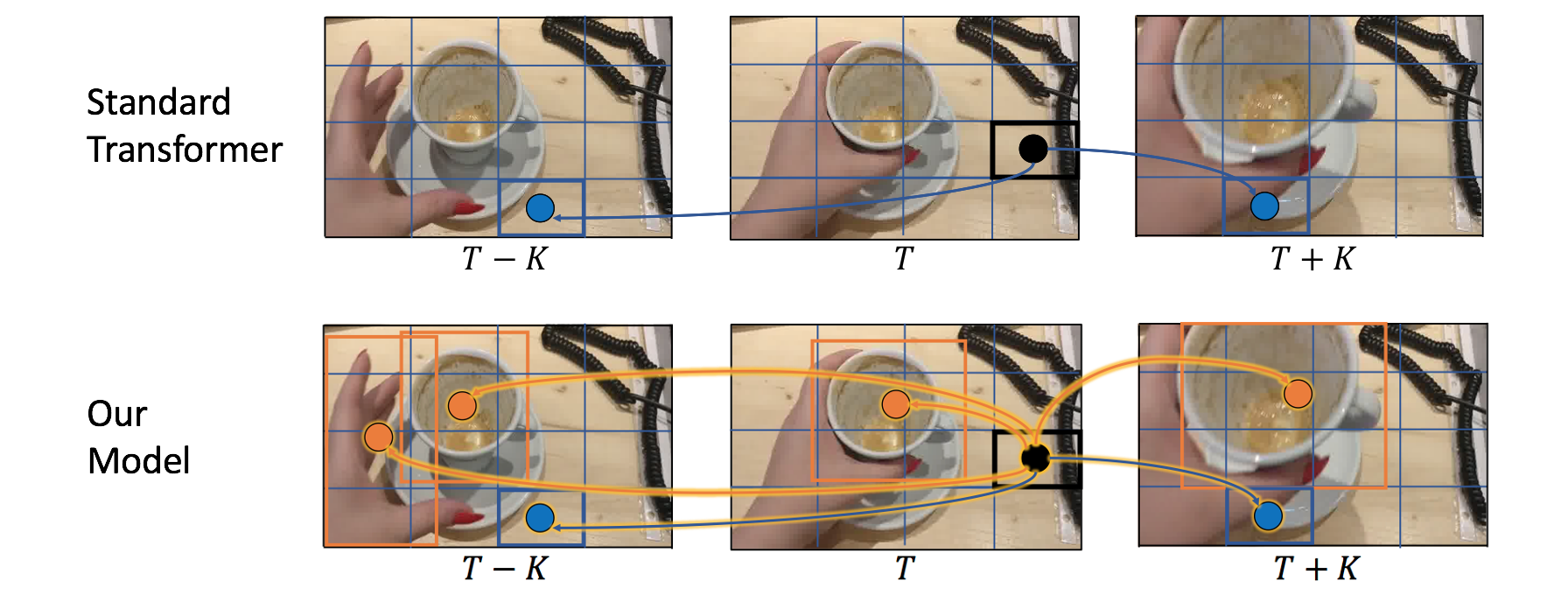
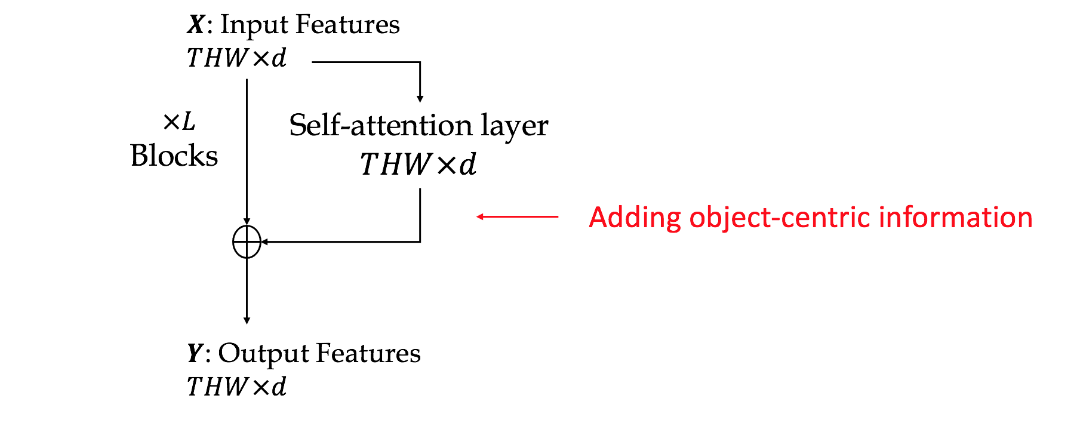
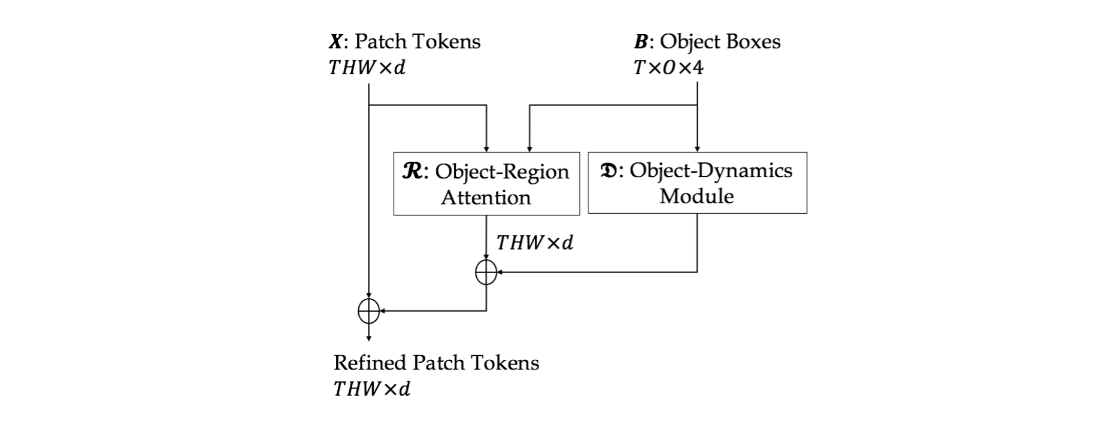
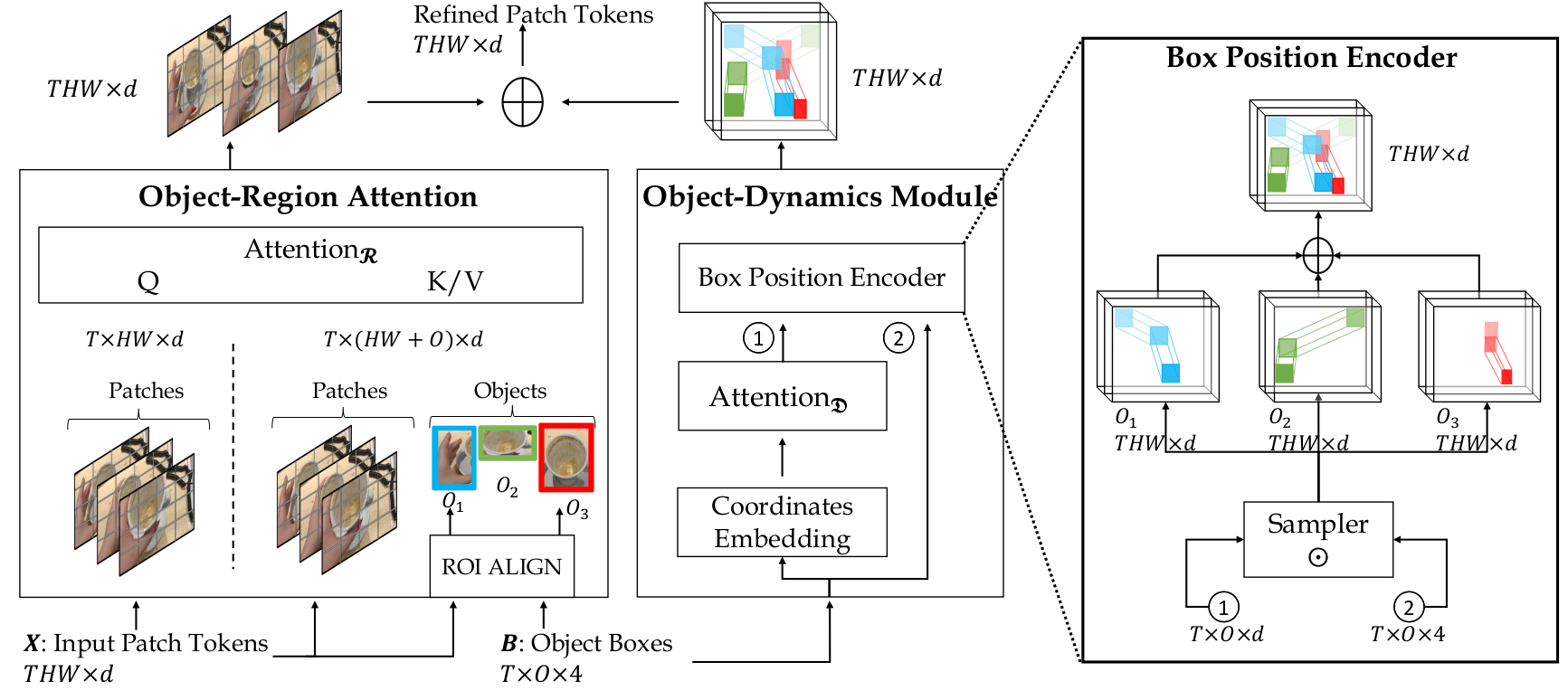
Consider the simple action of ''Picking up a coffee cup'' below. Intuitively, a human recognizing this action would identify the hand, the coffee cup and the coaster, and perceive the upward movement of the cup. This highlights three important cues needed for recognizing actions: What/where are the objects? How do they interact? and how do they move? Indeed, evidence from cognitive psychology also supports this structure of the action-perception system.
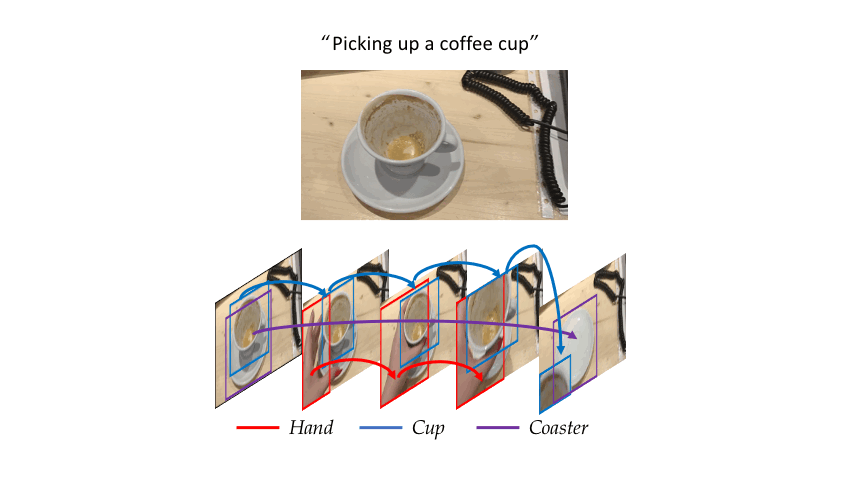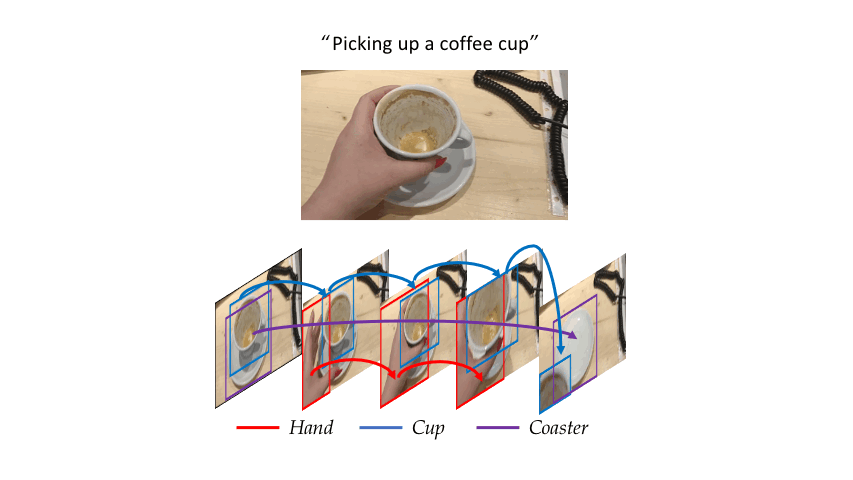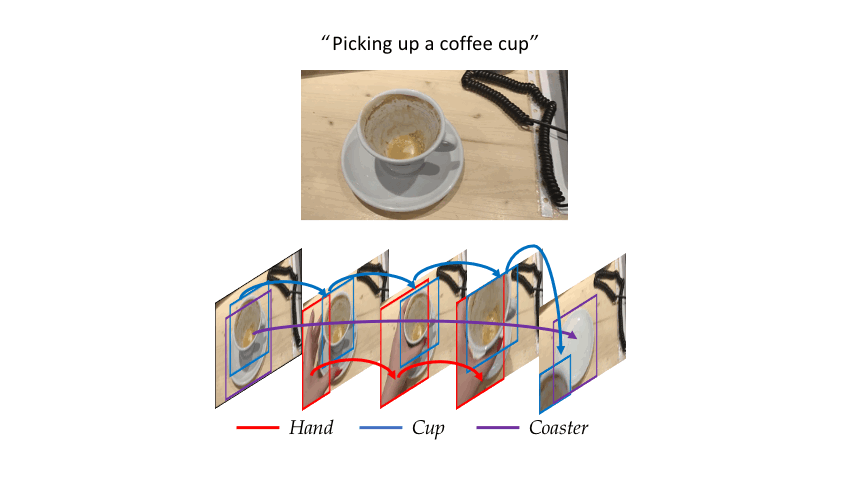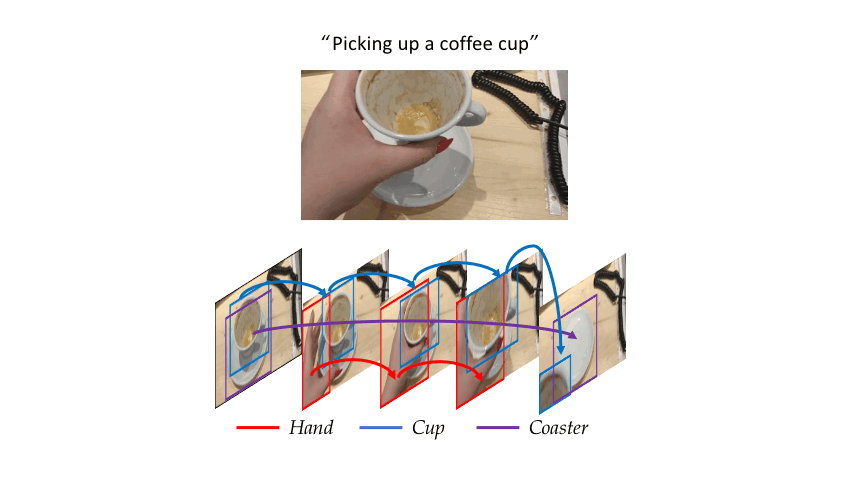
 |
Roei Herzig, Elad Ben-Avraham, Karttikeya Mangalam, Amir Bar, Gal Chechik, Anna Rohrbach, Trevor Darrell, Amir Globerson Object-Region Video Transformers CVPR, 2022 Hosted on arXiv |
Related Works |
Acknowledgements |